SYSTEMY OPERACYJNE
Wykład 6
Synchronizowanie procesów
- obie procedury są poprawne, jeśli są
rozpatrywane z osobna; mogą nie działać, gdy będą wykonywane współbieżnie:
Ogólna struktura typowego procesu Pi .
Struktura procesu Pi w algorytmie 1
-
#1: Algorytm 2
-
proces Pi
repeat
znacznik[i] := true;
while znacznik[j] do nic;
sekcja krytyczna
znacznik[i] := false;
reszta
until false;
Struktura procesu Pi w algorytmie 2
-
rozwiązanie spełnia warunek wzajemnego
wykluczania, ale nie spełnia warunku postępu
-
aby to zilustrować rozważmy następujący
ciąg wykonań:
| T0: |
P0 ustala znacznik[0] = true |
| T1: |
P1 ustala znacznik[1] = true |
po których procesy P0 i P1 zapętlają
się na zawsze w swoich instrukcjach while
- algorytm ten jest bardzo uzależniony od dokładnych
następstw czasowych obu procesów
- przedstawiona sekwencja może się zdarzyć w środowisku
kilku procesów działających współbieżnie lub jeśli jakieś
przerwanie (np. od czasomierza) wystąpi bezpośrednio po wykonaniu
kroku T0 i procesor zostanie przełączony z jednego procesu
do drugiego
#3 Algorytm 3
-
proces Pi
repeat
znacznik[i] := true;
numer := j;
while (znacznik[j]and numer=j) do nic;
sekcja krytyczna
znacznik[i] := false;
reszta
until false;
Struktura procesu Pi w algorytmie 3
var wybrane:
array [0..n-1] of boolean;
numer: array [0..n-1] of integer;
Na początku
elementy tych struktur danych przyjmują odpowiednio wartości
repeat
wybrane[i]:=true;
numer[i]:=max(numer[0],numer[1], ..., numer[n-1]) + 1;
wybrane[i]:=false;
for j:=0 to n-1
do begin
while wybrane[j]
do nic;
while numer[j]<>0
and (numer[j],i) < (numer[i],i) do nic;
end; |
sekcja krytyczna
reszta
until false;
- Sprzętowe środki synchronizacji
- właściwości sprzętu mogą pomóc w rozwiązaniu
problemu sekcji krytycznej;
- w środowisku jednoprocesorowym problem sekcji
krytycznej daje się łatwo rozwiązać jeżeli można zakazać występowania
przerwań podczas modyfikowania zmiennej dzielonej;
- to rozwiązanie jest nieprzydatne w środowisku
wieloprocesorowym: wymaga przekazywania komunikatów do wszystkich
procesorów i opóźnia wejście do sekcji krytycznej
- specjalne rozkazy sprzętowe typu Testuj-i-Ustal
pozwalające w sposób niepodzielny sprawdzić i zmienić zawartość
słowa
function
Testuj-i-Ustal(var cel:boolean):boolean;
begin
Testuj-i-Ustal:=cel;
cel:=true;
end;
- ważną cechą tego rozkazu jest jest jego
niepodzielne wykonanie, którego nie można przerwać;
- jeśli zatem dwa takie rozkazy są wykonywane
jednocześnie (każdy na innym procesorze), to będą wykonywane
sekwencyjnie w dowolnym porządku;
- wzajemne wykluczanie z Testuj-i-Ustal
- zmienna dzielona var
zamek:boolean początkowo false;
- proces Pi
repeat
| while Testuj-i-Ustal(zamek) do nic; |
sekcja krytyczna
reszta
until false
czekaj(S): while S<=
0 do nic;
S:=S-1;
sygnalizuj(S): S:=S+1;
- do rozwiązania problemu sekcji krytycznej z udziałem n
procesów
- dzielone zmienne: wspólny semafor mutex (ang.
mutal exclusion - wzajemne wykluczanie) - var
mutex: semaphore (początkowo mutex=1)
- proces Pi
repeat
sekcja krytyczna
reszta
until false
- do rozwiązywania różnych problemów synchronizacji,
np. dwa procesy współbieżne P1 z instrukcją S1 i P2 z instrukcją S2
chcemy, aby S2 została wykonana dopiero gdy zakończy się wykonanie S1
- schemat ten można czytelnie zrealizować, pozwalając
procesom P1 i P2 na dzielenie wspólnej zmiennej synch, z początkową
wartością 0, dołączając do procesu P1 instrucje
S1; sygnalizuj(synch);
oraz instrukcje
czekaj(synch); S2;
do procesu P2. Ponieważ początkowa wartość
zmiennej synch wynosi 0, więc proces P1 instrukcji sygnalizuj(synch),
umieszczonej po instrukcji S1
- problem poprzednich rozwiązań: konieczność
aktywnego czekania (wykonywanie instrukcji pętli w sekcji wejściowej)
przez procesy usiłujące wejść do sekcji krytycznej
- aby ominąć tą konieczność można zmodyfikować
semaforowe operacje czekaj i sygnalizuj
- semafor jako rekord:
type semaphore=record
wartość:integer;
L:list of proces;
end;
- dwie dodatkowe operacje (f. systemowe)
blokuj: zawiesza proces, który go wywołuje;
obudź(P): wznawia działanie zablokowanego procesu
- operacje semaforowe można zdefiniować teraz tak:
czekaj(S): S.wartość:=S.wartość-1;
if S.wartość<0
then begin
dołącz dany proces do S.L;
blokuj;
end;
sygnalizuj(S): S.wartość:=S.wartość-1;
if S.wartość<0
then begin
usuń jakiś proces P z S.L;
obudź(P);
end;
- decydujący aspekt poprawnego działania: niepodzielność
wykonania operacji czekaj i sygnalizuj na tym samym
semaforze w tym samym czasie
- w środowisku jednoprocesorowym można zabronić
wykonywania przerwań podczas wykonywania tych samych operacj
- Zakleszczenia i głodzenie
- zakleszczenie - dwa lub więcej procesów czeka w
nieskończoność na zdarzenie, które może być spowodowane tylko
przez jeden z czekających procesów
- załóżmy, że mamy dwa procesy P0 i P1, z których każdy
ma dosyęp do dwu semaforów S i Q ustawionych na 1:
P0
P1
czekaj(S);
czakaj(Q);
czekaj(Q);
czekaj(S);
.
.
.
.
sygnalizuj(S);
sygnalizuj(Q);
sygnalizuj(Q);
sygnalizuj(S);
- blokowanie nieskończone czyli głodzenie: procesy
czekają w nieskończoność pod semaforem (np. jeśli przy dodawaniu i
usuwaniu procesów z listy związanej z semaforem użyto porządku LIFO)
- poprzednio opisana konstrukcja semafora to tzw. semafor
zliczający - jego wartości całkowite mogą przebiegać dowolny
przedział;
- semafor binarny - wartość całkowita to tylko 0 i 1;
łatwiejsza implementacja
- implementacja semafora zliczającego S przy użyciu
semaforów binarnych
- struktury danych:
var S1:semafor-binarny;
S2:semafor-binarny;
C: integer;
- inicjalizacja
S1 = 1, S2 = 0 , C = początkowa wartość
semafora S
- operacja czekaj
czekaj(S1);
C:=C-1;
if C < 0
then begin
sygnalizuj(S1);
czekaj(S2);
end
sygnalizuj(S1);
- operacja sygnalizuj
czekaj(S1);
C:= C + 1;
if C <= 0
then sygnalizuj(S2);
else sygnalizuj(S1);
- Problem ograniczonego buforowania
- operujemy na puli n buforów
- semafor mutex umożliwia wzajemne wykluczanie
dostępu do puli buforów i ma wartość początkową 1;
- semafory pusty i pełny zawierają
odpowiednio liczbę pustych i pełnych buforów z wartościami początkowymi
n i 0 odpowiednio
- proces producenta
repeat
...
produkowanie jednostki
w nastp
...
czekaj(pusty);
czekaj(mutex);
...
dodanie jednostki nastp
do bufora bufor
...
sygnalizuj(mutex);
sygnalizuj(pełny);
until false;
- proces konsumenta
repeat
czekaj(pełny);
czekaj(mutex);
...
wyjmowanie
jednostki z bufora bufor do nastk
...
sygnalizuj(mutex);
sygnalizuj(pełny);
...
konsumowanie jednostki
z nastk
until false;
- Problem czytelników i pisarzy
- pierwszy problem czytelników i pisarzy: żaden nie
powinien czekać, chyba że właśnie pisarz otrzymał pozwolenie na używanie
obiektu dzielonego
- zmienna dzielona
var mutex, pis: semaphore;
liczba-czyt:
integer;
- proces pisarza
czekaj(pis);
...
tu następuje pisanie
...
sygnalizuj(pis);
- proces czytelnika
czytaj(mutex);
liczba-czyt:=liczba-czyt -
1;
if liczba-czyt
= 1 thenczekaj(pis);
sygnalizuj(mutex);
...
tu następuje czytanie
...
czekaj(mutex);
liczba-czyt:=liczba-czyt - 1;
if liczba-czyt = 0 then
sygnalizuj(pis);
sygnalizuj(mutex);
- zauważmy, że jeśli na pisarza przebywającego w
sekcji krytycznej oczekuje n czytelników, to jeden czytelnik stoi w
kolejce do semafora pis oraz n-1 czytelników ustawia się w
kolejce do semafora mutex. Gdy pisarz wykona operację, sygnalizuj(pis),
to można wznowić działanie czekających czytelników lub
pojedynczego pisarza
- Problem obiadujących filozofów
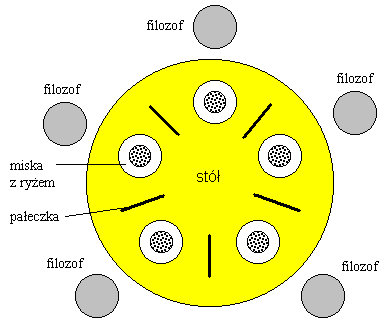
- zmienne dzielone
- każda pałeczka jest semaforem
var pałeczka: array[0..4]
of semaphore;
- początkowo wszystkie elementy tablicy = 1
- struktura i-tego filozofa
repeat
czekaj(pałeczka[i]);
czekaj(pałeczka[i
+1 mod 5]);
...
jedzenie
...
sygnalizuj(pałeczka[i]);
sygnalizuj(pałeczka[i
+ 1 mod 5]);
...
myślenie
...
until false;
- możliwość powstania zakleszczenia: np. wszyscy
filozofowie podnieśli jednocześnie pałeczkę ze swojej lewej
strony
var bufor: shared record
pula: array[0..n-1] of jednostka;
licznik, we, wy: integer;
end;
|
- proces produkujący umieszcza nazwę jednostki nast w buforze
dzielonym
region bufor when licznik < n
do begin
pula[we]:=nastp;
we:=we+1 mod n;
licznik:=licznik + 1;
end;
|
- proces konsumujący usuwa jednostkę z bufora dzielonego i zapamiętuje ją
w nastk za pomocą instrukcji:
region bufor when licznik > 0
do begin
nastk:=pula[wy];
wy:=wy+1 mod n;
licznik:=licznik-1;
end;
|
- Implementacja
warunkowego regionu krytycznego
- z każdą zmienną dzieloną kojarzy się następujące zmienne:
var mutex, pierwsza-zwłoka, druga-zwłoka: semaphore;
pierwszt-licznik, drugi-licznik: integer;
|
- początkowo mutex=1, pozostałe semafory mają wartość
0
Za wyłączność dostępu do sekcji krytycznej odpowiada
zmienna mutex. Jeśli proces nie może wejść do sekcji krytycznej z
powodu fałszywości warunku boolowskiego B, to najpierw czeka pod semaforem pierwsza-zwłoka.
Proces czekający pod semaforem pierwsza-zwłoka jest w końcu
przenoszony do semafora druga-zwłoka, co poprzedza udzielenie mu
zezwolenia na ponowne obliczenie boolowskiego B. Za pomocą zmiennych pierwszy-licznik
i drugi-licznik pamięta się odpowiednio ile procesów oczekuje pod
semaforami pierwsza-zwłoka i druga-zwłoka.
Jeśli jakiś proces opuszcza sekcję krytyczną, to może
zmienić wartość jakiegoś warunku boolowskiego B, wzbraniającego innemu
procesowi wejścia do sekcji krytycznej. Biorąc to pod uwagę, należy przejrzeć
kolejkę procesów czekających pod semaforami pierwsza-zwłoka i dryga-zwłoka
(w tej kolejności) i pozwolić, by każdy proces przetestował wyrażenie
boolowskie. Proces testujący to wyrażenie może odkryć, że jego obecna wartość
jest równa true. Wówczas proces wchodzi do sekcji krytycznej. W
przeciwnym razie proces musi nadal czekać pod semaforami pierwsza-zwłoka
i druga-zwłoka, jak opisaliśmy poprzednio.
-
jeśli jakiś proces opuszcza sekcję krytyczną, to może
zmienić wartość jakiegoś warunku boolowskiego B, wzbraniającego innemu
procesowi wejście do sekcji
-
należy więc przejrzeć kolejkę procesów czekających pod
semaforami pierwsza-zwłoka i dryga-zwłoka i pozwolić, aby każdy proces
przetestował wyrażenie boolowskie
-
proces testujący może odkryć, że jego obecna wartość
jest równa true, wówczas proces wchodzi do sekcji krytycznej
-
w przeciwnym razie proces musi nadal czekać pod semaforem
-
mając więc daną zmienną x, instrukcję:
można zrealizować:
czekaj(mutex);
while not B
do begin
pierwszy-licznik:=pierwszy-licznik + 1;
if drugi-licznik > 0
then sygnalizuj(druga-zwłoka)
else sygnalizuj(mutex);
czekaj (pierwsza-zwłoka);
pierwszy-licznik:=pierwszy-licznik - 1;
drugi-licznik:=drugi-licznik + 1;
if pierwszy-licznik > 0
then sygnalizuj(pierwsza-zwłoka)
else sygnalizuj(drugi-licznik);
czekaj(druga-zwłoka);
drugi-licznik:=drugi-licznik - 1;
end;
S;
if pierwszy-licznik > 0
then sygnalizuj(pierwsza-zwłoka)
else if drygi-licznik > 0
then sygnalizuj(druga-zwłoka)
else sygnalizuj(mutex);
|
- implementacja konstrukcji regiony warunkowego
-
transakcja
- zbiór instrukcji (operacji) które wykonują logicznie spójną
funkcję (program) i które muszą być wykonane niepodzielnie,
tzn. albo wszystkie operacje zostaną wykonane albo żadna nie będzie
wykonana.
-
niepodzielność
musi być zachowana pomimo ewentualnych awarii systemu komputerowego
-
należy
zapewnić niepodzielność wykonywania transakcji w środowisku gdzie
awaria systemu spowoduje utratę informacji w pamięci ulotnej
-
techniki
baz danych a SO-e
-
cechy
urządzeń stosowanych do przechowywania danych, z których korzystają
transakcje
-
Pamięć
ulotna (ang. volatile storage): Informacje przechowywane w
pamięci ulotnej na ogół nie są w stanie przetrwać awarii systemu.
Przykładem tego rodzaju pamięci są: pamięć operacyjna (główna)
oraz pamięć podręczna. Dostęp do pamięci ulotnych jest
najszybszy, zarówno z powodu swoistych ich szybkości jak i dlatego,
że dowolną jednostkę danych uzyskuje się z pamięci ulotnej w sposób
bezpośredni.
-
Pamięć
nieulotna (ang. nonvolatile storage): Informacje
przechowywane w pamięci nieulotnej zwykle potrafią przetrwać awarie
systemu. Przykładami nośników takiej pamięci są dyski i taśmy
magnetyczne. Dyski są bardziej niezawodne niż pamięć operacyjna,
lecz mniej niezawodne niż taśmy magnetyczne. Jednak zarówno dyski,
jak i taśmy magnetyczne są narażone na uszkodzenia, które mogą powodować
utratę informacji. Obecnie wytwarzane pamięci nieulotne są
wolniejsze od pamięci ulotnych o kilka rzędów wielkości, ponieważ
dyski i taśmy magnetyczne są urządzeniami elektromechanicznymi, w
których dostęp do danych wymaga ruchu.
-
Pamięć
trwała (ang. stable storage): Informacje przechowywane w
pamięci trwałej nie giną nigdy ("nigdy" należy tu
potraktować z pewnym dystansem, gdyż teoretycznie taka 100 %-wa
gwarancja nie jest możliwa). Do implementacji przybliżenia takiej
pamięci należy zastosować zwielokrotnienie informacji w kilku
nieulotnych pamięciach podręcznych (zazwyczaj dyskach), niezależnie
od siebie na wypadek awarii, oraz uaktualnić te informacje w sposób
kontrolowany
-
odtwarzanie
za pomocą rejestru
-
rejestrowanie z
wyprzedzeniem - wszystkie zmiany wykonywane przez transakcję w
danych, do których ona ma dostęp są rejestrowane w pamięci trwałej,
w strukturze danych nazywanej rejestrem (dziennikiem).
-
każdy rekord rejestru
opisuje jedną operację pisania w transakcji i ma pola:
-
rejestr posiada rekord <Ti,
rozpoczęcie>
-
każda operacja pisz
w transakcji jest poprzedzona zapisaniem odpowiedniego rekordu
-
gdy dochodzi do
zatwierdzenia transakcji, wówczas w rejestrze zapisuje się
rekord <Ti , zatwierdzenie>, a w wypadku
przeciwnym < Ti , anulowano>
-
algorytm rekonstrukcji
korzysta z dwóch procedur
-
wycofaj ( Ti
) - odtwarza wszystkie dane uaktualnione przez transakcję Ti
, nadając im stare wartości; procedura jest aktywowana gdy
rejestr zawiera rekord <Ti, rozpoczęcie>
lecz nie zawiera <Ti , zatwierdzenie>
-
przywróć ( Ti
) - nadaje nowe wartości wszystkim danym uaktualnionym przez Ti
; jest aktywizowana gdy rejestr zawiera oba rekordy <Ti,
rozpoczęcie> i <Ti , zatwierdzenie>
-
punkty kontrolne
1. Wszystkie rekordy aktualnie
pozostające w pamięci ulotnej (zazwyczaj w pamięci operacyjnej) mają
być
zapisane w pamięci trwałej
2. Wszystkie zmienione dane
pozostające w pamięci ulotnej mają być umieszczone w pamięci trwałej
3. W przechowywanym w pamięci
trwałej rejestrze transakcji należy zapisać rekord <punkt
kontrolny>
-
po wystąpieniu awarii
procedura rekonstrukcji przegląda rejestr w celu odnalezienia
ostatniej transakcji Ti , której wykonanie rozpoczęto
przed wykonaniem ostatniego punktu kontrolnego
-
wsteczne
przeszukiwanie rejestru w celu napotkania pierwszego rekordu <
punkt kontrolny>
-
odnalezienie
pierwszego rekordu <Ti , rozpoczęcie> występującego
po nim
-
operacje przywróć
i wycofaj wystarczy wykonać tylko dla Ti i
wszystkich transakcji rozpoczętych po niej
-
współbieżne transakcje
niepodzielne
-
szeregowalność - transakcje
są wykonywane sekwencyjnie (jedna po drugiej) i każda z nich jest
wykonywana w sekcji krytycznej
-
przykład seryjnego planu
wykonywania niepodzielnych transakcji, w których T0
poprzedza T1
| T0 |
T1 |
| czytaj(A) |
|
| pisz(A) |
|
| czytaj(B) |
|
| pisz(B) |
|
| |
czytaj(A) |
| |
pisz(A) |
| |
czytaj(B) |
| |
pisz(B) |
Plan
1, czyli plan szeregowy, w którym transakcja T0 poprzedza transakcję
T1
-
jeśli zezwolimy na
przeplatanie się instrukcji wchodzących w skład dwóch transakcji, to
wynikowy plan przestaje być szeregowym; czy szeregowy plan musi pociągać
za sobą błąd w ostatecznym wyniku?
-
zdefiniujmy pojęcie operacji
konfliktowych: operacje Oi oraz Oj należące
odpowiednio do Ti i Tj pozostają w konflikcie, jeżeli
mają dostęp do tych samych obiektów danych i co najmniej jedna z nich
jest operacją pisania
-
przeanalizujmy nieszeregowy
plan 2
| T0 |
T1 |
| czytaj(A) |
|
| pisz(A) |
|
| |
czytaj(A) |
| |
pisz(A) |
| czytaj(B) |
|
| pisz(B) |
|
| |
czytaj(B) |
| |
pisz(B) |
Plan
2: szeregowalne zaplanowanie współbieżne
-
jeśli
zezwolimy na przeplatanie się instrukcji wchodzących w skład
transakcji, to wynikowy plan przestaje być szeregowy; czy nieszeregowy
plan musi pociągać za sobą błąd w ostatecznym wyniku?
-
zdefiniujmy
pojęcie operacji konfliktowych: operacje Oi oraz Oj
należące odpowiednio do Ti i Tj pozostają w
konflikcie, jeśli mają dostęp do tych samych obiektów danych
i co najmniej jedna z nich jest operacją pisania
-
przeanalizujmy
nieszeregowy plan 2:
|
T0
|
T1 |
| czytaj(A) |
|
| pisz(A) |
|
| |
czytaj(A) |
| |
pisz(A) |
| czytaj(B) |
|
| pisz(B) |
|
| |
czytaj(B) |
| |
pisz(B) |
. . . . . -
operacje konfliktowe
. . . . . -
operacje niekonfliktowe
-
jeżeli sąsiednie operacje Oi
i Oj w planie P są operacjami w różnych transakcjach, i te
operacje nie są w konflikcie, to wolno nam zamienić porządek tych
operacji, co daje nowy plan P'
-
można oczekiwać, że plan P będzie równoważny
planowi P' (kolejność operacji Oi i Oj jest bez
znaczenia)
-
tak więc operację Pisz(A) należącą
do T1 można zamienić z Czytaj(B) należącą do T0
-
kontynuując zamienianie bezkonfliktowych
operacji uzyskujemy w efekcie plan 1, czyli plan szeregowy.
-
plany te więc są równoważne; mówimy,
że plan P jest szeregowalny z uwzględnieniem konfliktów
-
protokół blokowania
-
jeden ze sposobów zapewnienia
szeregowalności polega na skojarzeniu z każdym obiektem danych zamka
i wymaganiu, aby w każdej teansakcji przestrzegano protokołu
blokowania
-
dane mogą być blokowane w następujących
trybach:
-
tryb wspólny: jeśli
transakcja Ti zajmuje obiekt danych w trybie wspólnym,
to może ona czytać ten obiekt, lecz nie może go zapisywać.
-
tryb wyłączny: jeśli
transakcja Ti zajmuje obiekt danych w trybie wyłącznym,
to może ona czytać ten obiekt, jak i go zapisywać.
wymaga się, aby każda transakcja
zamawiająca zamek blokujący obiekt danych Q w odpowiednim trybie
stosownie od rodzaju operacji, które będzie ona na Q wykonywać
aby uzyskać dostęp do obiektu Q,
transakcja musi go najpierw zablokować
-
- faza wzrostu: transakcja może zablokować
zasób, lecz nie wolno jej zwolnić żadnych z już zablokowanych
zasobów
-
- faza zmniejszania: transakcja może zwolnić
zasób, lecz nie wolno jej już blokować nowych zasobów
- ten protokół zapewnia szeregowalność pod względem
konfliktów, nie chroni jednak przed zakleszczeniami
- protokoły korzystające ze znaczników czasu
- schemat uporządkowania według znacznika czasu
- inna metoda określania kolejności transakcji polegająca na ich
uporządkowaniu z góry:
- z każdą transakcją Ti w systemie
kojarzymy niepowtarzalny i stały znacznik czasu ZC(Ti)
- jeżeli transakcji przypisano znacznik ZC(Ti)
i w późniejszym czasie pojawi się nowa transakcja Tj,
to ZC(Ti) < ZC(Tj)
- w celu implementacji tego schematu z każdym obiektem
danych Q kojarzymy dwa znaczniki czasu
- znacznik czasu - P(Q), określający największy
znacznik czasu transakcji, która pomyślnie wykonała operację pisz(Q)
- znacznik czasu - C(Q), określający największy
znacznik czasu transakcji, która pomyślnie wykonała operację czytaj(Q)
-
Załóżmy, że transakcja Ti
wydaje polecenie czytaj(Q)
Jeśli ZC(Ti) <
znacznik_czasu_P(Q), to z tego wynika, że transakcja Ti
chce czytać wartość Q, która już została zmieniona. Dlatego
operacja czytaj zostaje odrzucona, a transakcja Ti -
wycofana.
Jeśli ZC(Ti) >=
znacznik_czasu_P(Q), to wykonuje się operację czytaj oraz
określa znacznik_czasu_C(Q) jako maksimum z wartości
znacznik_czasu_C(Q) i ZC(Ti).
-
Załóżmy, że transakcja Ti
wydaje polecenie pisz(Q)
Jeśli ZC(Ti) <
znacznik_czasu_C(Q), to z tego wynika, że wytwarzana przez transakcję
Ti wartość Q, była potrzebna wcześniej i przyjmuje się
że transakcja Ti nigdy nie wytworzyła tej wartości.
Wobec tego rezygnuje się z operacji pisz i wycofuje transakcję
Ti .
Jeśli ZC(Ti) >=
znacznik_czasu_P(Q), to z tego wynika, że transakcja Ti
usiłuje zapisać przestarzałą wartość Q. Dlatego odrzuca się tę
operację pisz i wycofuje transakcję (Ti).
rozpatrzmy plan3; zakładamy, że
transakcjom przypisuje się znacznik czasu tuż przed ich pierwszymi
instrukcjami, zatem ZC(T2) < ZC(T3); rozpatrzony
ciąg wykonywań może być wytworzony protokół blokowania dwufazowego
| T2 |
T3 |
| czytaj(B) |
|
| |
czytaj(B) |
| |
pisz(B) |
| czytaj(A) |
|
| |
czytaj(A) |
| |
pisz(A) |
Plan 3: zaplanowanie możliwe przy użyciu
protokołu ze znacznikami czasu
<<< THE END >>>