SYSTEMY OPERACYJNE
Wykład 5
Planowanie przydziału procesora
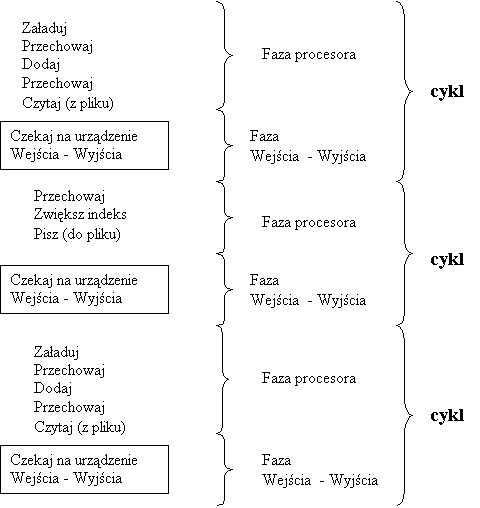
Naprzemienny ciąg faz procesora i wejścia - wyjścia.
cel wieloprogramowania: maksymalizowanie wykorzystania jednostki centralnej przez stałe utrzymywanie w działaniu pewnej liczby procesów (wieloprogramowanie).
wykonanie procesu składa się z następujących po sobie cykli:
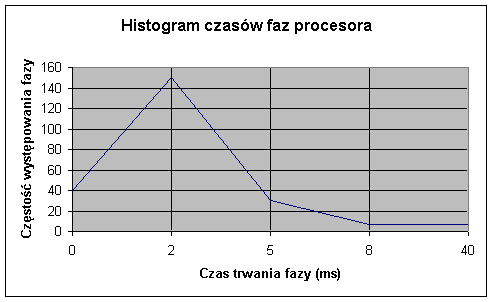
eksperymentalna krzywa rozkładu częstości okresów zatrudnienia procesora przez proces: wiele krótkich faz procesora i mało długich faz.
Planista przydziału procesora: wybiera jeden proces spośród przebywających w pamięci procesów gotowych i przydziela mu procesor.
decyzje o przydziale procesora mogą zapaść, gdy:
Proces przeszedł od stanu aktywności do stanu czekania (np. z powodu zamówienia na WE/WY lub rozpoczęcia czekania na zakończenie działania któregoś z procesów potomnych)
Proces przeszedł od stanu aktywności do stanu gotowości (np. wskutek wystąpienia przerwania)
proces przeszedł od stanu czekania do stanu gotowości (np. po zakończeniu operacji WE/WY)
Proces kończy działanie.
jeśli planowanie odbywa się tylko w sytuacjach 1 i 4 to mówimy o niewywłaszczeniowym planowaniu (w przeciwnym wypadku planowanie jest wywłaszczeniowe).
program ekspediujący: moduł, który faktycznie przekazuje procesor do dyspozycji procesu wybranego przez planistę krótkoterminowego; do jego obowiązków należy:
przełączanie kontekstu
przełączanie do trybu użytkownika
wykonanie skoku do odpowiedniej komórki w programie użytkownika w celu wznowienia działania programu.
opóźnienie ekspedycji - czas zużyty przez ekspedytora na wstrzymanie procesu i uaktywnienie innego
Kryteria planowania
do porównywania algorytmów planowania zaproponowano wiele kryteriów; uwzględniają one poniższe właściwości:
Wykorzystanie procesora: Dąży się do tego. aby procesor był nieustannie zajęły pracą. Wykorzystanie procesora może się wahać w granicach od 0 do 100%. W rzeczywistym systemie powinno się ono mieścić w przedziale od 40% (słabe obciążenie systemu) do 90% (intensywna eksploatacja systemu).
Przepustowość: Jeśli procesor jest zajęty wykonywaniem procesów, to praca postępuje naprzód. Jedną z miar pracy jest liczba procesów kończonych w jednostce czasu zwana przepustowością (ang. throughput). Dla długich procesów wartość ta może wynosić jeden proces na godzinę. Dla krótkich transakcji przepustowość może się kształtować na poziomie 10 procesów na sekundę.
Czas cyklu przetwarzania: Ważnym kryterium dla konkretnego procesu jest czas potrzebny na jego wykonanie. Czas upływający między chwilą nadejścia procesu do systemu a chwilą zakończenia procesu nazywa się czasem cyklu przetwarzania (ang. turnaround time). Jest to suma okresów spędzonych na czekaniu na wejście do pamięci, czekaniu w kolejce, procesów gotowych do wykonania, wykonywaniu procesu przez procesor i wykonywaniu operacji wejścia-wyjścia.
Czas oczekiwania: Algorytm planowania przydziału procesora nie ma faktycznie wpływu na czas, w którym proces działa lub wykonuje operacje wejścia-wyjścia: dotyczy on tylko czasu, który proces spędza w kolejce procesów gotowych do wykonania. Czas oczekiwania jest sumą okresów, w których proces czeka w kolejce procesów gotowych do działania.
Czas odpowiedzi: W systemach interakcyjnych czas cyklu przetwarzania może nie być najlepszym kryterium. Często bywa tak, że proces produkuje pewne wyniki dość wcześnie i wykonuje następne obliczenia, podczas gdy poprzednie rezultaty są prezentowane użytkownikowi. Toteż kolejną miarą jest czas upływający między wysłaniem żądania (przedłożeniem zamówienia) a pojawieniem się pierwszej odpowiedzi. Ta miara, nosząca nazwę czasu odpowiedzi (ang. response time), określa, ile czasu upływa do rozpoczęcia odpowiedzi, ale nie obejmuje czasu potrzebnego na wyprowadzenie tej odpowiedzi. Czas odpowiedzi jest na ogół uzależniony od szybkości działania urządzenia wyjściowego.
Algorytmy planowania
Planowanie metodą FCFS (FIFO)
przykład
Proces Czas trwania fazy P1 24 P2 3 P3 3
załóżmy, że procesy nadeszły w kolejności P1, P2, P3
diagram Gantta dla algorytmu szeregowania:
P1 P2 P3
0
24 27 30
czas oczekiwania dla P1=0, P2=24, P3=27
średni czas oczekiwania: (0+24+27)/3=17
załóżmy, że procesy nadeszły w kolejności: P2, P3, P1
diagram Gantta:
P2 P3 P1
0 3
6
30
czas oczekiwania dla P1=0, P2=3, P3=6
średni czas oczekiwania: (6+0+3)/3=3 i jest dużo lepszy niż poprzednim przypadku
efekt konwoju: krótkie procesy czekają na zakończenie długiego procesu
Planowanie metodą "najpierw najkrótsze zadanie (SJF - shortest-job-first)
algorytm wiąże z każdym procesem długość jego najbliższej z przyszłych faz procesora; dostępny procesor zostaje przydzielony procesowi z najkrótszą następną fazą
dwa warianty
niewywłaszczający - proces - któremu przydzielono procesor nie może być wywłaszczony dopóki nie zakończy się bieżąca faza
wywłaszczający - jeżeli przybywa nowy proces z czasem trwania fazy mniejszym aniżeli czas pozostały do zakończenia bieżącego procesu. Ten schemat nazywny jest jest planowaniem metodą "najpierw najkrótszy pozostały czas"
SJF - jest algorytmem optymalnym: daje minimalny średni czas oczekiwania dla danego zbioru procesów.
przykład SJF - NIEWYWŁASZCZAJĄCY
Proces Czas Przybycia Czas trwania fazy P1 0,0 7 P2 2,0 4 P3 4,0 1 P4 5,0 4
diagram Gantta
P1 P3 P2 P4
|
0 |
7 8 |
12 |
16 |
średni czas oczekiwania=(0+6+3+7)/4=4
przykład SJF - WYWŁASZCZAJĄCY
Proces Czas Przybycia Czas trwania fazy P1 0,0 7 P2 2,0 4 P3 4,0 1 P4 5,0 4
diagram Gantta
|
P1 |
P2 | P3 | P2 | P4 | P1 |
|
0 2 |
4 5 |
7 |
11 |
16 |
średni czas oczekiwania=(9+1+0+2)/4=3
jak określić długość następującego zapotrzebowania procesu na procesor?
można tylko oszacować długość następnej fazy procesora
można to zrobić na podstawie znanych już poprzednich faz procesora, używając średniej wykładniczej pomiarów poprzednich faz
tn = aktualna długość n-tej fazy procesora
Tn+1 = przewidywalna wartość długości fazy procesora w każdej chwili n+1
a,0 <= a <= 1
zdefiniujemy
Tn+1 = a*tn + (1-a)*Tn
przykłady średniej wykładniczej
a = 0
Tn+1 = Tn
niedawna historia nie ma wpływu na wynik
a = 1
Tn+1 = Tn
liczy się tylko ostatnia wartość pomiaru fazy procesora
można rozwinąć wzór:
Tn+1 = a*tn + (1-a)*a*tt-1 + ... + (1-a)j *a*tn-j + ... + (1-a)n+1 *T0
ponieważ zarówno (a) jak i (1-a) są mniejsze niż lub równe 1, to każdy następny człon ma mniejszą wagę niż jego poprzednik
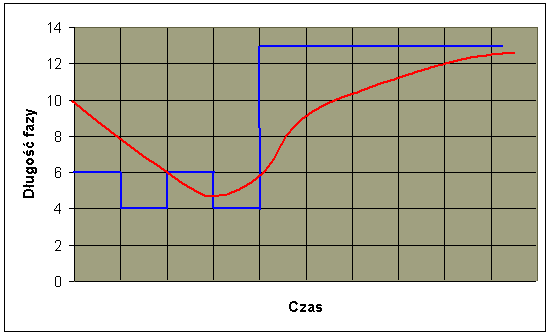
Faza procesora (tj) 6 4 6 4 13 13 13 ...
Wartość "odgadnięta" (Tj) 10 8 6 6 5 9 11 12 ... Przewidywanie następnych faz procesora na postawie średniej wykładniczej
jeszcze jeden przykład planowania SJF wywłaszczającego
Proces Czas przybycia Czas trwania fazy P1 0 8 P2 1 4 P3 2 9 P4 3 5
P1 P2 P4 P1 P3
| 0 1 |
5 |
10 |
17 |
26 |
Planowanie priorytetowe
Każdemu procesowi przypisuje się priorytet (liczbę całkowitą)
procesor przydziela sie procesowi, którego priorytet jest majwyższy (mniejsza liczba = wiekszy priorytet)
PP z wywłaszczaniem
PP bez wywłaszczania
poprzedni SJF jest algorytmem PP, w którym priorytetem jest oczekiwany (przewidywalny) następny czas trwania fazy
Proces Czas trwania fazy Prioorytet P1 10 3 P2 1 1 P3 2 3 P4 1 4 P5 5 2 Przy zastosowaniu planowania priorytetowego otrzymujemy takie jak na poniższym diagramie Gantta:
P2 P5 P1 P3 P4
|
1 |
6 |
16 |
18 |
19 |
Problem = głodzenie - procesy z niskim priorytetem mogą nigdy nie doczekać się procesora
Rozwiązanie = postarzanie - stopniowe podwyższanie priorytetu długo oczekującego procesu.
Planowanie rotacyjne (round-robin-RR)
zaprojektowano specjalnie dla systemów z podziałem czasu
- każdy proces otrzymuje małą jednostkę czasu procesora (kwant czasu), zwykle 10-100 milisekund. Po upływie tego czasu proces jest wywłaszczany i wstawiany na koniec kolejki gotowych procesów. Tę kolejkę obsługuje się zgodnie z regułą FIFO
- średni czas oczekiwania w RR jest dość długi
- przykład: t=0; kwant czasu=4ms
Proces Czas trwania fazy P1 24 P2 3 P3 3
- wykres Gantta
P1 P2 P3 P1 P1 P1 P1 P1
0 4
10
14
18
22
26
26 30
średni czas oczekiwania =17/3=5.66 ms

jeśli jest n gotowych do wykonania procesów w kolejce, a kwant czasu wynosi q, to każdy proces dostaje 1/n czasu procesora porcjami, których wielkość nie przekracza q jednostek czasu, żaden proces nie czeka dłużej niż (n-1)q jednostek czasu
wydajność algorytmu
q duże => FIFO
q małe => q musi być duże w stosunku do czasu przełączania kontekstu
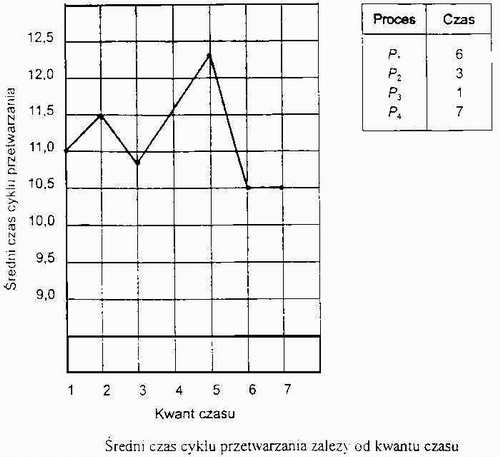
czas cyklu przetwarzania zależy od rozmiaru kwantu
jeśli kwant czasu jest za duży to RR degeneruje się do schematu FCFS
wypróbowana reguła: 80% faz procesora powinno być krótszych niż jeden kwant czasu
Wielopoziomowe planowanie kolejek
kolejkę procesów gotowych rozdziela się na osobne kolejki;
kolejkę procesów pierwszoplanowych (foreground)
kolejkę procesów drugoplanowych (background)
każda kolejka posiada własny algorytm planowania
procesy pierwszoplanowe - RR
procesy drugoplanowe - FCFS
musi istnieć planowanie między kolejkami
stało-priorytetowe planowanie, tzn. obsłuż wszystkie pierwszoplanowe procesy, a następnie procesy drugoplanowe; możliwość głodzenia
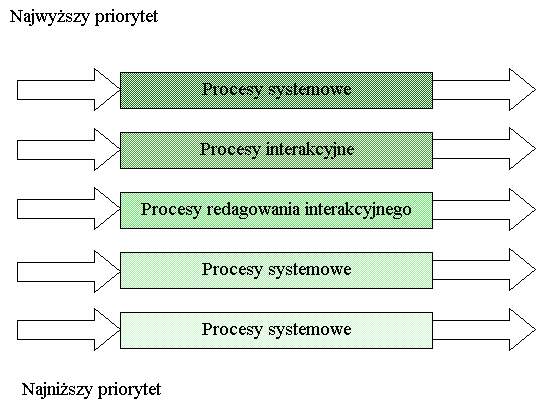
Wielopoziomowe planowanie kolejek
1. Procesy systemowe
2. Procesy interakcyjne
3. Procesy redagowania interakcyjnego
4. Procesy wsadowe
5. Procesy studenckie
operowanie kwantami czasu - każda kolejka otrzymuje określoną wielkość czasu procesora, która jest rozplanowywana między swoimi procesami, np.
80% dla procesów pierwszoplanowych w RR
20% dla procesów drugoplanowych w FCFS
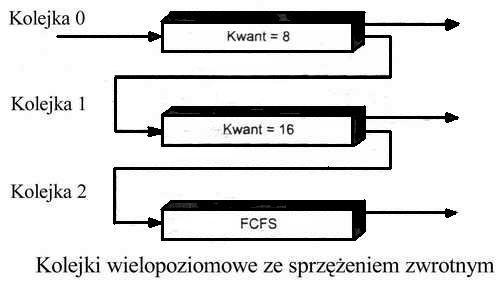
Planowanie wielopoziomowych kolejek ze sprzężeniem zwrotnym
proces może przemieszczać się między różnymi kolejkami
koncepcja algorytmu polega na rozdzieleniu procesów o różnych rodzajach faz procesora; jeśli proces zużywa za dużo procesora, to zostanie przeniesiony do kolejki o niższym priorytecie (np. z kolejki 0 do kolejki 1)
planista wielopoziomowych kolejek ze sprzężeniem zwrotnym jest określony za pomocą następujących parametrów:
liczby kolejek;
algorytmu planowania dla każdej kolejki
metody użytej do decydowania o awansowaniu procesu do kolejki o wyższym priorytecie;
metody użytej do decydowania o zdymisjonowaniu procesu do kolejki o niższym priorytecie;
metody wyznaczającej kolejkę, do której trafia proces potrzebujący obsługi.
jest to najogólniejszy algorytm planowania; można go modyfikować
niestety wymaga też sposobu wybierania wartości wszystkich parametrów definiujących najlepszego planistę
Planowanie wieloprocesorowe
gdy dostępnych jest wiele procesorów, problem planowania ich pracy komplikuje się
załóżmy, że wszystkie procesory systemu są identyczne (homogeniczne)
dzielenie obciążeń: wspólna kolejka procesów gotowych, które są przydzielane do dowolnego z dostępnych procesorów
każdy procesor sam planuje swoje działanie; problemy synchronizacji
jeden z procesorów pełni funkcję planisty (struktura typu master-slave); ta struktura jeszcze bardziej rozbudowana prowadzi do przetwarzania asymetrycznego
Planowanie w czasie rzeczywistym
Rygorystyczne systemy czasu rzeczywistego - potrzebne do wypełniania krytycznych zadań w gwarantowanym czasie
na podstawie danych dostarczanych wraz z procesem planista akceptuje ten proces, zapewniając jego wykonanie na czas, lub odrzuca jako zlecenie niewykonalne
niezbędne jest specjalne oprogramowanie
Łagodne systemy czasu rzeczywistego
wymaga się od nich, aby procesy o decydującym znaczeniu miały priorytet nad słabiej sytuowanymi
system musi mieć planowanie priorytetowe, a procesy działające w czasie rzeczywistym muszą mieć największy priorytet, który nie może maleć z upływem czasu
opóźnienie ekspediowania procesów do procesora musi być małe
aby utrzymać opóźnienie ekspedycji na niskim poziomie musimy zezwolić na wywłaszczanie funkcji systemowych
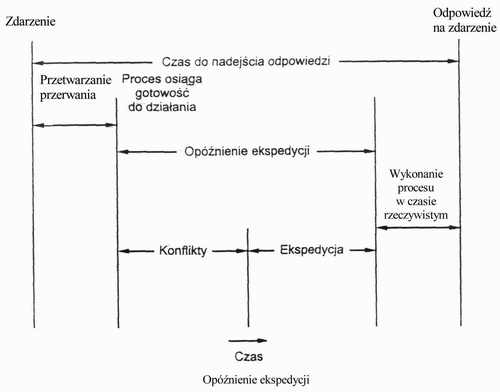
inna metoda - wywłaszczanie całego jądra
faza konfliktowa w opóźnieniu ekspedycji składa się z 3 części:
1. Wywłaszczenie procesu działającego w jądrze.
2. Zwolnienie przez niskopriorytetowe procesy zasobów potrzebnych procesowi
wysokopriorytetowemu.
3. Przełączenie kontekstu z procesu bieżącego do procesu wysokopriorytetowego.
Ocena algorytmiki planowania
jak wybrać algorytm planowania przydziału procesora dla konkretnego systemu?
podstawowym problemem jest zdefiniowanie kryteriów stosowanych przy wyborze algorytmu
pod uwagę można wziąć miary takie jak:
maksymalizacja wykorzystania procesora przy założeniu, że maksymalny czas odpowiedzi wyniesie 1 s.
maksymalizacja przepustowości w taki sposób, aby czas cyklu przetwarzania był (średnio) liniowo proporcjonalny do ogólnego czasu wykonania
istnieje kilka metod oceny algorytmów planowania
Modelowanie deterministyczne
przyjmuje się konkretne, z góry określone obciążenie robocze systemu i definiuje zachowanie każdego algorytmu w warunkach tego obciążenia
założone obciążenie {
systemu
Proces Czas trwania fazy P1 10 P2 29 P3 3 P4 7 P5 12 {
FCFS:
P1 P2 P3 P4 P5
0 10
39
42
49
61
średni czas oczekiwania: (0+10+39+42+49)/5=28 ms
SJF
P3 P4 P1 P5 P2
0
3
10
20
32 61
średni czas oczekiwania: (10+32+0+3+20)/5=13 ms
Rotacyjne (kwant czasu = 10 ms)
P1 P2 P3 P4 P5 P2 P5 P2
0
10
P3 20 23 30
40
50
52
61
średni czas oczekiwania =23 ms
wymaga zbyt wiele dokładnej wiedzy
Modele obsługi kolejek (sieci kolejek)
model kolejkowy
- --------> }|}|}|}|}|}----( I )------>
n - średnia długość kolejki
W - średni czas oczekiwania w kolejce
lambda - średnia liczba przybywających do kolejki procesów (np. 3 procesy/sec)
n = lambda * W
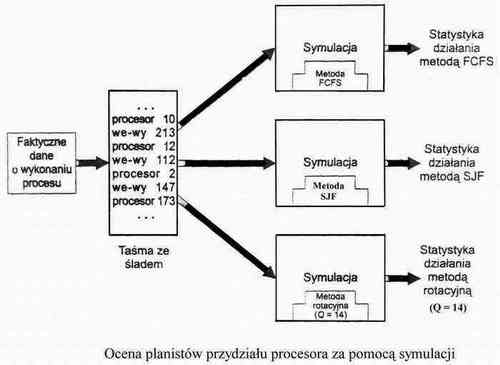
Symulacje
<<< THE END >>>