SYSTEMY OPERACYJNE
Wykład 4
Procesy
- Planowanie procesów
- celem wieloprogramowania jest jak najlepsze wykorzystanie procesora - powinien on
zawsze wykonywać jakiś proces
- w podziale czasu przełączanie procesora do procesów powinno następować tak
często, aby każdy z wykonywanych programów mógł współpracować z użytkownikami w
sposób interaktywny

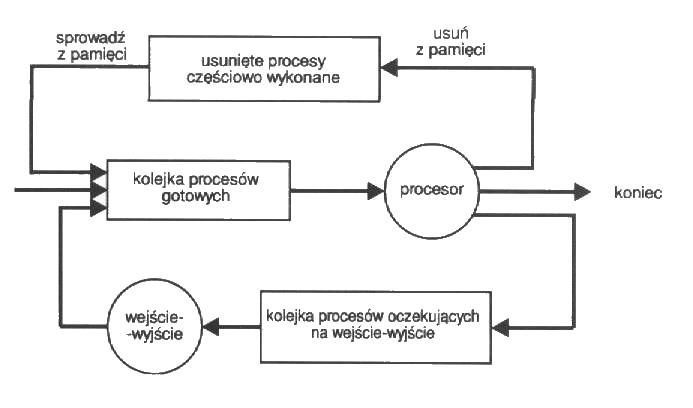
- Kolejki planowania
- Kolejka zadań - zbiór wszystkich procesów systemu
- Kolejka procesów gotowych - zbiór wszystkich procesów, które
oczekują w pamięci głównej, gotowych i oczekujących na wykonanie
- Kolejki do urządzeń - zbiór procesów oczekujących na
urządzenia WE/WY
- migracja procesów między kolejkami systemu

Po przydzieleniu procesowi procesora może wystąpić jedno z następujących
zdarzeń:
- proces może zamówić operację WE/WY, wskutek czego trafia do kolejki procesów
oczekujących na WE/WY
- proces może utworzyć nowy podproces i oczekiwać na jego zakończenie
- w wyniku przerwania proces może zostać przymusowo usunięty z procesora z powrotem
do kolejki procesów gotowych
- Planiści
W celu planowania działań SO musi w
jakiś sposób wybierać procesy z kolejki; selekcji dokonuje proces systemowy zwany planistą
(scheduler)
- planista długoterminowy (job scheduler) - wybiera procesy przechowywane w
pamięci masowej (dysk) i ładuje je do pamięci, do kolejki zadań (procesów gotowych)
- planista krótkoterminowy (CPU scheduler) - wybiera jeden proces, który
ma być wykonywany jako następny i przydziela mu procesor
- planista krótkoterminowy musi bardzo często wybierać nowy proces dla procesora
(milisekundy) ==> musi być szybki.
- planista długoterminowy działa o wiele rzadziej (sekundy,
minuty) ==> może
być wolniejszy
- planista długoterminowy nadzoruje stopień wieloprogramowości
- procesy można podzielić na:
- procesy ograniczone przez WE/WY: większość czasu spędzają na wykonywaniu
operacji WE/WY
- procesy ograniczone przez dostęp do procesor
- planista długoterminowy musi dobrać dobrą mieszankę procesów
- w niektórych SO z podziałem czasu może występować pośredni poziom planowania
==> planista pośredni
- Przełączanie kontekstu
- gdy CPU przełącza się do innego procesu to system musi przechować stan starego
procesu i załadować przechowywany stan nowego procesu; nazywa się
to przełączaniem
kontekstu
- czas przełączania kontekstu jest obciążeniem dla systemu, które nie jest
związane z żadną użyteczną pracą
- czas ten zależy w dużym stopniu od możliwości sprzętu

- Działania na procesach
- Tworzenie procesu
- proces macierzysty (parent process) tworzy procesy zwane potomkami
(children) ==>drzewo procesów
- dzielenie zasobów
- proces macierzysty i potomkowie dzielą wszystkie zasoby
- potomkowie dzielą podzbiór procesu macierzystego
- proces macierzysty i potomkowie nie dzielą wspólnych zasobów
- wykonywanie procesów
- proces macierzysty kontynuuje działanie współbieżne ze swoimi potomkami
- proces macierzysty oczekuje na zakończenie działania niektórych lub
wszystkich swoich procesów potomnych
- przestrzeń adresowa
- proces potomny staje się kopią procesu macierzystego
- proces potomny otrzymuje nowy program
- w UNIX-ie
- nowy proces tworzy sie za pomocą funkcji systemowe fork; zawiera
on kopię przestrzeni adresowej procesu pierwotnego
- funkcja systemowa execve ładuje plik binarny do pamięci
(niszcząc obraz pamięci programu zawierającego execve) i rozpoczyna
jego wykonywanie
- proces macierzysty może tworzyć następnych potomków, lub użyć funkcji
systemowej wait aby usunąć się z kolejki gotowych procesów, do chwili
zakończenia procesu potomnego
- Kończenie procesu
- proces wykonuje swoją ostatnią instrukcję i prosi SO (funkcja
systemowa exit), aby go usunął
- może wtedy przekazać dane do procesu macierzystego, za pośrednictwem
funkcji systemowej wait
- zasoby procesu (pamięć fizyczna i wirtualna, otwarte pliki, bufory
WE/WY ) zostają odebrane przez SO
- proces macierzysty może zakończyć wykonywanie procesu potomnego za
pomocą funkcji systemowej, np. abort
- gdy potomek nadużył któregoś z przydzielonych mu zasobów
- gdy wykonywane przez potomka zadanie stało się zbędne
- gdy proces macierzysty kończy się
- SO nie pozwala potomkowi na dalsze działanie, gdy proces macierzysty
kończy się
- kończenie kaskadowe (wszystkich potomków)
- proces jest niezależny (nie dzieli żadnych danych z innym
procesem) jeżeli nie może oddziaływać na inne procesy, a one też nie mogą wpływać
na jego działanie
- proces jest współpracujący, jeżeli może wpływać na inne procesy
lub inne procesy mogą wpływać na niego
- zalety współpracy procesów:
- dzielenie informacji
- przyspieszanie obliczeń
- modularność wygoda
- Zagadnienie producenta - konsumenta
- popularny paradygmat (wzorzec) współpracujących procesów; producent
wytwarza informację, którą zużywa proces konsument
- potrzebny bufor jednostek informacji, aby umożliwić producentowi i
konsumentowi działanie współbieżne
- nieograniczony bufor
- ograniczony bufor: konsument musi czekać jeżeli bufor jest pusty, a
producent musi czekać jeżeli bufor jest pełny
- procesy producenta i konsumenta muszą podlegać synchronizacji, aby
konsument nie próbował korzystać z tego co nie zostało wyprodukowane
# Rozwiązanie problemu
dla ograniczonego buforu i pamięci dzielonej
- procesy producenta i konsumenta korzystają z następujących wspólnych
zmiennych:
var n;
type jednostka=...;
var bufor: array [0...n-1] of jednostka;
we, wy: 0..n-1;
repeat
...
produkuj jednostkę w nastp
...
while we+1 mod n=wy do nic;
bufor[we] :=nastp;
we:=we+1 mod n;
until false;
repeat
while we=wy do nic;
nastk :=bufor[wy];
wy :=wy+1 mod n;
....
konsumuj jednostkę z nastk
....
until false;
dany schemat pozwala na
użycie co najwyżej n-1 jednostek w buforze w tym samym czasie
bufor może być udostępniony
przez SO za pomocą komunikacji międzyprocesowej lub może być jawnie zakodowany przez
programistę aplikacji
wspólne zmienne:
we i wy mają
nadaną wartość początkową 0
dzielony bufor jest
zrealizowany jako tablica cykliczna z dwoma wskaźnikami logicznymi: we i wy
zmienna we, wskazuje na
następne wolne miejsce w buforze; zmienna wy wskazuje na pierwsze zajęte miejsce w
buforze
bufor jest pusty, gdy we=wy;
jest pełny gdy we+1 mod n=wy
proces producenta ma lokalną
zmienną nastp, w której przechowuje nowo produkowaną jednostkę
proces konsumenta ma lokalną
zmienną nastk, w której jest przechowywana jednostka do skonsumowania
wątek ( lub proces
lekki) jest podstawową jednostką wykorzystania procesora; zawiera on:
licznik rozkazów
zbiór rejestrów
obszar stosu
wątek współużytkuje wraz z
innymi równorzędnymi wątkami:
proces tradycyjny czyli ciężki
jest równoważny zadania z jednym wątkiem
zadanie nie robi nic jeśli
nie ma w nim ani jednego wątku; z kolei wątek może przebiegać w dokładnie jednym
zadaniu
przełączanie procesora
między równorzędnymi wątkami jest tanie w porównaniu z przełączaniem kontekstu
między tradycyjnymi procesami ciężkimi (nie trzeba wykonywać żadnych prac związanych
z zarządzaniem pamięcią)
w niektórych systemach
zrealizowano też wątki poziomu użytkownika, z których korzysta się za
pośrednictwem wywołań bibliotecznych zamiast odwołań do systemu dzięki czemu
przełączanie wątków nie wymaga wzywania SO i przerwań związanych z przechodzeniem do
jądra
każdy z wielu procesów
działa niezależnie od innych (własny licznik rozkazów, rejestr stosu, przestrzeń
adresowa)
taka organizacja jest wygodna
wówczas, gdy zadania wykonywane przez procesy nie są ze sobą powiązane
wiele procesów może też
wykonywać to samo zadanie, np. w realizacji sieciowego systemu plików, wiele procesów
może dostarczać danych do odległych maszyn
do obsługi tego samego
przedsięwzięcia wydajniej jest zastosować jeden proces z wieloma wątkami
w realizacji wieloprocesorowej
każdy proces wykonuje ten sam program, ale we własnej pamięci i przy użyciu własnych
plików
jeden proces wielowątkowy
zużywa mniej zasobów niż zwielokrotnione procesy

działanie wątków pod
wieloma względami przypomina działanie procesów (stany wątku, jeden watek aktywny,
tworzenie wątków potomnych, blokowanie się do czasu zakończenia wywołań systemowych)
w odróżnieniu od procesów,
wątki nie są niezależne od siebie, ponieważ wszystkie wątki mają dostęp do każdego
adresu w zadaniu, dany watek może czytać i zapisywać stosy dowolnych innych wątków
w zadaniu z wieloma wątkami,
gdy jeden z wątków usługowych (sieciowy system plików) jest zablokowany i czeka, w tym
samym zadaniu może działać inny wątek ( w przypadku wielu procesów żaden inny proces
usługowy nie może działać dopóty, dopóki pierwszy proces nie zostanie odblokowany)
współpraca wielu wątków
jednego zadania umożliwia większą przepustowość systemu i polepsza jego wydajność
w problemach, które wymagają
dzielenia wspólnego zasobu - (np. problem producenta - konsumenta) bufora, wątki
- producent i konsument tego samego zadania będą mogły być przełączane tanim
kosztem, a w systemie wieloprocesorowym będą mogły działać równoległe na dwóch
procesorach
wątki tworzą mechanizm
umożliwiający procesom sekwencyjne wykonywanie blokowanych wywołań systemowych przy
jednoczesnym osiąganiu równoległości
istnieje wiele alternatywnych
sposobów traktowania wątków:
wątki obsługiwane przez
jądro (Mach, OS/2)
tworzenie wątków powyżej
jądra SO za pomocą zbioru funkcji bibliotecznych wykonywanych na poziomie użytkownika
(projekt Andrew z CMU, Java)
hybrydowe podejście:
implementacja zarówno wątków obsługiwanych przez jądro, jak też wątków z poziomu
użytkownika

Solaris 2,
wersja systemu UNIX z wątkami na poziomie jądra i użytkownika, symetrycznym
wieloprzetwarzaniem i planowaniem w czasie rzeczywistym
również zdefiniowano
pośredni poziom wątków - procesy lekkie; każde zdanie (nazywane
"procesem") zawiera co najmniej jeden proces lekki
wątkami poziomu użytkownika
obdziela się procesy lekkie; wykonywaniem zadania zajmują się tylko te wątki poziomu
użytkownika, które są aktualnie podłączone do procesu lekkiego; pozostałe są
zablokowane
zasoby potrzebne wątkom:
wątek jądrowy ma jedynie
małą strukturę danych i stos. Przełączanie wątków jądrowych nie wymaga zmiany
informacji dotyczących dostępu do pamięci, jest więc stosunkowo szybkie
proces lekki (LWP) zawiera
blok kontrolny procesu z danymi rejestrowymi, informacjami rozliczeniowymi i informacjami
dotyczącymi pamięci. przełączanie procesów lekkich wymaga zatem nieco pracy i jest
dość wolne
watek poziomu użytkownika
wymaga tylko stosu i licznika rozkazów - nie są mu potrzebne żadne zasoby jądra.
Jądro nie jest angażowane w planowanie wątków poziomu użytkownika, tak więc ich
przełączanie jest szybkie. Mogą istnieć tysiące wątków poziomu użytkownika, a
jedyne, co będzie widoczne dla jądra, to procesy lekkie w procesie realizującym wątki
tego poziomu
Komunikacja
międzyprocesorowa
SO powinien posiadać środki
pozwalające procesom na komunikowanie się oraz synchronizację ich działań
system komunikacji
międzyprocesowej (SKM)- procesy komunikują się za pomocą przekazywanych komunikatów,
bez uciekania się do zmiennych dzielonych
SKM umożliwia wykonanie
dwóch podstawowych operacji:
jeżeli procesy P i Q chcą
się komunikować to muszą:
implementacja łącza
komunikacyjnego:
fizyczna (np. pamięć
dzielona, szyna sprzętowa, sieć)
logiczna (np. cechy logiczne)
jak ustanawia się
połączenia?
czy łącze może być
powiązane z więcej niż dwoma procesami?
ile może być łączy między
każdą parą procesów?
jaka jest pojemność łącza?
czy łącze ma jakiś obszar buforowy? jeśli tak, to jak duży?
jaki jest rozmiar
komunikatów? czy łącze akceptuje komunikaty zmiennej, czy stałej długości?
czy łącze jest
jednokierunkowe, czy dwukierunkowe? jeśli istnieje łącze między P i Q, to czy
komunikaty mogą przepływać tylko w jedną stronę (np. tylko od P do Q), czy w obie?
repeat
...
wytwarzaj jednostkę w nastp
...
nadaj (konsument, nastp);
until false;
repeat
odbierz (producent, nastk);
...
konsumuj jednostkę z nastk;
...
until false;
#2:
Komunikacja pośrednia
komunikaty są nadawane i
odbierane za pośrednictwem skrzynek pocztowych, nazywanych także portami
każda skrzynka pocztowa ma
jednoznaczną identyfikację
procesy mogą komunikować
się tylko wtedy, gdy mają wspólną skrzynkę pocztową
własności łącza
komunikacyjnego:
łącze między dwoma
procesami jest ustanawiane tylko wtedy, gdy dzielą one jakąś skrzynkę pocztową
łącze może być związane z
więcej niż dwoma procesami
każda para komunikujących
się procesów może mieć kilka różnych łączy, z których każde odpowiada jakiejś
skrzynce pocztowej
łącze może być
jednokierunkowe lub dwukierunkowe
wspólne dzielenie skrzynki
pocztowej
P1, P2 i P3 wspólnie dzielą
skrzynkę pocztową A
P1 wysyła komunikat do A; P2
i P3 kierują do skrzynki operację odbierz
kto otrzyma komunikat?
rozwiązania:
zezwalać na łącza tylko
między dwoma procesami
pozwalać tylko co najwyżej
jednemu procesowi na wykonanie w danej chwili operacji odbierz
dopuścić, aby system
wybierał dowolnie proces, do którego dotrze komunikat (tzn. komunikat otrzyma albo P1,
albo P2, albo nie oba procesy); system może informować nadawcę o ostatecznym odbiorcy
kolejka komunikatów (liczba
komunikatów, które mogą przebywać w łączu) jest implementowana w jeden ze sposobów:
pojemność zerowa:
maksymalna długość kolejki wynosi 0, czyli łącze nie dopuszcza, by czekał w nim
jakikolwiek komunikat. W tym przypadku nadawca musi czekać, aż odbiorca odbierze
komunikat. Aby można było przesyłać komunikaty, oba procesy muszą być
zsynchronizowane - synchronizacje taką nazywa się rendez-vous.
pojemność ograniczona:
kolejka ma skończona długość n, może w niej zatem pozostawać co najwyżej n
komunikatów. Jeśli w chwili nadania nowego komunikatu kolejka nie jest pełna, to nowy
komunikat zostaje w niej umieszczony (przez skopiowanie komunikatu lub zapamiętanie
wskaźnika do niego) i nadawca może kontynuować działanie bez czekania. Jednak kiedy
łącze z powodu ograniczonej pojemności ulegnie zapełnieniu, wtedy nadawca będzie
musiał być opóźniany, aż zwolni się miejsce w kolejce.
pojemność nieograniczona:
kolejka ma potencjalnie nieskończoną długość; może w niej oczekiwać dowolna liczba
komunikatów. Nadawca nigdy nie jest opóźniany.
w przypadku niezerowych
pojemności, nadawca musi jawnie skontaktować się z odbiorcą, aby sprawdzić, czy ten
ostatni otrzymał przesyłkę:
nadaj (Q, komunikat);
odbierz (Q, komunikat);
Proces Q wykonuje instrukcje:
odbierz (P, komunikat);
nadaj (P, "potwierdzenie");
<<< THE END >>>


