w sieciach z komutacją pakietów przesyłane są między węzłami bloki danych (nazywane na tym poziomie ramkami), a nie strumienie bitów
adaptery - elementy sieci odpowiedzialne za wymianę ramek
węzeł A chce nadać ramkę do B
w tym celu powiadamia swój adapter
powoduje to pojawienie się sekwencji bitów przesyłanych w łączu
adapter B gromadzi razem sekwencję bitów przychodzących z łącza i umieszcza ramkę w pamięci węzła B
który zbiór bitów stanowi ramkę (jej początek, jej koniec) - podstawowe zadanie adaptera
Protokoły znakowe (BISYNC, IMP-IMP, DDCMP)
spojrzenie na ramkę jak na zbiór bajtów (znaków), a nie jak na zbiór bitów, to jedno z najstarszych podejść do rozpoznawania ramek
protokoły reprezentujące takie podejście ukierunkowane bajtowo (byte-oriented) to
BISYNC (Binary Synchronous Communication) opracowany w IBM
DDCMP (Digital Data Communication Message Protocol) stosowany w sieci DECENET firmy Digital Equipment Corp.
IMP-IMP stosowany w pierwszej sieci ARPANET (IMP - Interface Message Procesor - tak nazywano pierwotnie węzły komutacji pakietów w sieci ARPANET)
te protokoły, podobne pod wieloma względami, stosują jedną z dwóch technik rozpoznawania ramek: podejście z wyróżnionym znakiem lub podejście zliczające znaki
Format ramki w protokole IMP-IMP
#1 podejście z wyróżnionym znakiem (sentinel approach)
protokoły BISYNC i IMP-IMP stosują tę technikę rozpoznawania ramek
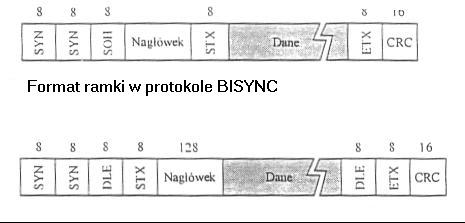
formaty ich ramek przedstawiono na rysunku ; te ramki (pakiety) przedstawiają sobą sekwencję etykietowanych pól z określoną długością mierzoną w bitach
początek ramki jest oznaczony przez nadanie specjalnego znaku SYN, zwanego znakiem synchronizacji (synchronization character)
dane w ramce są umieszczone między dwoma wyróżnionymi znakami (sentinel characters)
w protokole BISYNC, dane są umieszczone między znakami STX (start of text)- początek tekstu i ETX (end of text)- koniec tekstu
w protokole IMP-IMP dane są umoeszczone między znakami DLE/STX i DLE/ETX (DLE - data-link-escape - opuszczenie łącza danych)
w ramce protokołu BISYNC pole SOH (start of header - początek nagłówka) pełni tę samą rolę, co pole STX
problem dla obu protokołów w podejściu z wyróżnionym znakieme może być to, że znak ETX może pojawić się w części ramki zawierającej dane
protokół przezwycięża ten problem poprzez unikanie (escaping) znaku ETX przez poprzedzenie go znakiem DLE kiedykolwiek znak ETX pojawia się wewnątrz ramki; DLE unika się przez poprzedzenie go dodatkowym znakiem DLE
Format ramki w protokole DDCMP
ponieważ protokół IMP-IMP już umieszcza znak DLE przed znakami STX i ETX to musi on jedynie unikać znaku DLE w części ramki zawierającek dane
oba formaty ramek zawierają pole CRC (cyclic redudancy check- cykliczna kontrda nadmiarowa), które jest stosowane do wykrywania błędów transmisjiz
#2 podejście zliczające znaki (byte- counting approach)
protokół DDCMP stosuje pole licznik podające liczbę znaków zawartych w ramce
problem: błąd transmisji może zniekształcić pole licznika - odbiornik będzie gromadził znaki aż do nadejścia kolejnego SYN
Format ramki w protokole HDLC
Protokoły bitowe (HDLC)
protokoły bitowe nie są związane z granicami znaków - widzą one ramkę jako zbiór bitów
początek i koniec ramki są rozpoznawane na podstawie wyróżnionej sekwencji bitów
opracowano szereg protokołów bitowych
SDLC (Synchronous Data Link Control) opracowany przez IBM
po dokonaniu normalizacji tego protokołu przez OSI otrzymano protokół HDLC (High-Level Data Link Control) (patrz, rysunek)
najnowszy protokół PPP (Point-to-Point Protocol) jest podobny do HDLC
w protokole HDLC początek i koniec ramki jest oznaczony przez sekwencję bitów 01111110
Ta sekwencja jest również nadawana, gdy łącze jest bezczynne - nadajnik i odbiornik mogą wtedy synchronizowac swoje zegary
ta wyróżniona sekwencja bitów może jednak pojawić się też gdziekolwiek w ramce (problem)
dlatego protokoły bitowe stosują analogię do znaku DLE, mianowicie technikę zwaną wstawianiem bitów (bit stuffing)
wstawianie bitów w protokole HDLC
po kolejnych 5-ciu nadanych jedynek pochodzących z wnętrza komunikatu (a więc spoza wyróżnionej sekwencji), nadajnik wprowadza 0 przed nadaniem kolejnego bitu
odbiornik po otrzymaniu 5-ciu jedynek musi podjąć decyzje na podstawie następnego bitu, po tych 5-ciu kolejnych jedynkach
następnym bitem było 0 - musiał być wcześniej wstawiony (stuffed) i odbiornik usuwa go
następny bit to 1 (2 możliwości)
(a) albo jest to znacznik końca ramki
(b) albo jest to błąd
decyzja o tym czy to przypadek (a) czy (b) jest podejmowana na podstawie kolejnego bitu, który może być
0, co oznacza koniec ramki
1, błąd - ramka jest odrzucona i odbiornik czeka na kolejną sekwencję 01111110, zanim ponownie rozpocznie odbiór
zauważmy, że konsekwencją wstawiania bitów jest zależność rozmiaru ramki od przesłanych danych
Rozpoznawanie ramek za pomocą zegara (SONET)
trzecie podejście do rozpoznawania ramek jest określone przez normę sieci SONET (Synchronous Optical Network - synchroniczna sieć światłowodowa)
podejście to jest nazywane również jako rozpoznawanie ramek za pomocą zegara (clock-based framing)
historia sieci SONET
sieć zaproponowana przez firmę Bellcore (Bell Communications Research)
następnie opracowana przez ANSI (American National Standarts Institute - Amerykański Instytut Normalizacji) dla celów cyfrowej transmisji w łączu światłowodowym
ostatecznie przyjęta przez ITU-T (Sekcję Norm Telekomunikacyjnych Międzynarodowej Unii Telekomunikacyjnej)
norma sieci SONET jest skomplikowana - określa ona jak przekazywać dane w sieci światłowodowej

Format ramki STS-1 w sieci SONET
SONET podejmuje zarówno problem rozpoznawania ramek jak i problem kodowania, również problem multipleksacji kilku wolnych łączy na jedno szybkie łącze
rozpoznawanie ramek w sieci SONET - rozważmy tę kwestię dla najwolniejszego łącza w sieci, STS-1, działającego z szybkością 51,84 Mb/s
ramka STS-1 zawiera 9 wierszy po 90 bajtów
pierwsze 3 bajty każdego wiersza to bajty organizacyjne, a reszta jest dostępna dla danych
pierwsze 2 bajty ramki zawierają specjalny wzór bitów, które pozwalają odbiornikowi określić początek ramki
nie ma gwarancji, że ten wzór nie pojawi się czasami w części organizacyjnej
odbiornik poszukuje specjalnego wzorca stale mając nadzieję, że pojawi się on raz na każde 9*90 = 810 bajtów
szczegółowy opis wykorzystania wszystkich bajtów organizacyjnych jest złożony, w szczególności dlatego, że SONET jest uruchomiony na dostarczonej przez operatora (firmę świadczącą usługi transmisji danych) sieci światłowodowej, a nie na pojedynczym łączu
bajty organizacyjne w ramce sieci SONET są kodowane za pomocą NRZ ; aby zapewnić wiele przejść pozwalających odbiornikowi odzyskać zegar nadajnika, bajty organizacyjne są zaszyfrowane przez zmieszanie sygnałów (scrambled)
zaszyfrowanie odbywa się przez obliczenie różnicy symetrycznej (exclusive OR) (XOR) danych nadawanych i dobrze znanego wzorca bitowego o długości 127 bitów, z wieloma przejściami od jedynki do zera
multipleksacja wielu wolnych łączy
dane łącze w sieci działa na jednej - ze skończonego zbioru możliwych - szybkości
szybkości te zmieniają się od 51,84 Mb/s (STS-1) do 2488,32 Mb/s (STS-48) i dalej
wszystkie szybkości są całkowitą wielokrotnością STS-1
dla rozpoznawania ramki ma to takie znaczenie, że pojedyncza ramka w sieci może zawierać podramki dla wielu kanałów o niższej szybkości
drugą związaną z tym cechą jest to, że każda ramka ma długość 125ms
to oznacza , że przy szybkości STS-1, ramka sieci ma długość 810 bajtów, a przy szybkości STS-3, każda ramka ma długość 2430 bajtów - trzy ramki STS-1 mieszczą się w jednej ramce STS-3
intuicyjnie ramka STS-N może być wyobrażona jako składająca się z N ramek STS-1, gdzie ramki są przeplatane - bajt z pierwszej ramki jest transmitowany, następnie bajt z drugiej ramki, itd.
przyczyną przeplatania bajtów z każdej ramki STS-N jest zapewnienie, aby w każdej ramce STS-1 bajty były dostarczone w tym samym tempie
bajty pojawiają się w odbiorniku płynnie z szybkością 51 Mb/s, a nie gromadzą się przy każdej 1/N z przedziału 125
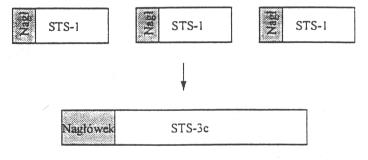
Trzy ramki -1 multipleksowane w jedną ramkę STS-3c
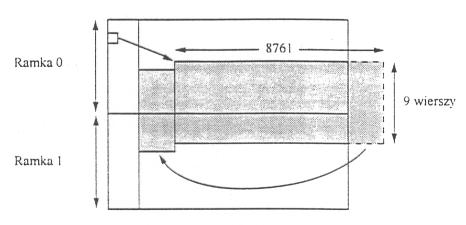
Ramki sieci SONET nie będące w fazie
chociaż możemy uważać sygnał STS-N jako multipleksację N ramek STS-1, to ładunek (payload) z ramek STS-1 może być połączony w celu utworzenia większego ładunku ramki STS-N
takie łącze nazywamy STS-Nc (c - od concatenated - poddany konkatenacji
rysunek pokazuje konkatenacje w przypadku trzech ramek STS-1 poddanych konkatenacji w pojedynczą ramkę STS-3c
STS-3c to łącze, które można traktować jak pojedynczą rurę o przepustowości 155,25 Mb/s, a STS-3 jako trzy łącza przepustowości 51,84 Mb/s, które współdzielą światłowód

historia technik radzących sobie z błędami bitowymi w systemach komputerowych jest długa i zaczyna się od kodów Hamminga i Reeda / Solomona (zapamiętywanie danych na dyskach magnetycznych i pamięciach rdzeniowych)
w sieciach komputerowych dominującą metodą wykrywania błędów transmisji jest technika znana jako cykliczna kontrola nadmiarowa (cyclic redundancy check - CRC)
jest ona stosowana w prawie wszystkich protokołach warstwy łącza omówionych wcześniej - protokołach IMP - IMP, HDLC, DDCMP - jak również w protokołach sieci CSMA i sieci pierścieniowej ze znacznikiem
inne podejście do wykrywania błędów to
dwuwymiarowa parzystość ( two dimensional parity) - protokół BISYNC przy transmisji znaków ASCII
sumy kontrolne (chek - sums) - niektóre protokoły w Internecie
Cykliczna kontrola nadmiarowa
schemat ten opiera się na dodaniu informacji nadmiarowej do ramki
przy przesłaniu n - bitowego komunikatu, musimy dodatkowo przesłać k nadmiarowych bitów, gdzie k << n
np. w sieciach Ethernet ramka przenosząca 1200 bitów (150 bajtów) danych wymaga jedynie 32 - bitowego kodu CRC ( CRC - 32 )
do wykrywania błędów potrzebny jest odpowiednio silny aparat matematyczny
załóżmy, że n bitowy komunikat jest przedstawiony przez wielomian stopnia n-1, gdzie wartość każdego bitu ( 0 lub 1) jest współczynnikiem członu w wielomianie, np. komunikat zawierający bity
1 0 0 1 1 0 1 0
7 6 5 4 3 2 1 0
odpowiada wielomianowi
M(x) = x7+ x4 + x3 + x1
C(x) = x3 + x2 + 1
stopień tego wielomianu, k = 3
wielomianowi odpowiada liczba binarna
1101
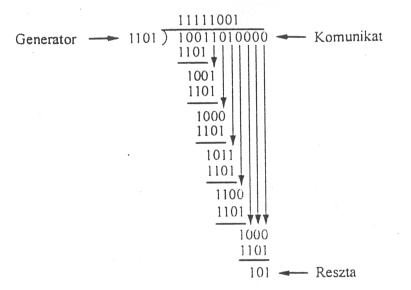
Obliczenia CRC za pomocą dzielenia pisemnego.
(x7 + x4 + x3 + x1 ) * x3 = x10 + x7 + x6 + x4
otrzymanemu wielomianowi odpowiada kod
1 0 0 1 1 0 1 0 0 0 0
10 9 8 7 6 5 4 3 2 1 0
C(x) = x3 + x2 + 1
któremu odpowiada 1 1 0 1
wynik pisemnego dzielenia wielomianów przedstawiono wyżej
należy wiedzieć, że wynikiem dzielenia wielomianu B(x) przez wielomian C(x) będący tego samego rzędu co B(x) będzie pewien wielomian, a resztą z dzielenia będzie różnica symetryczna (XOR) wielomianów B(x) i C(x)
z przeprowadzonego dzielenia wynika reszta równa 1 0 1
stąd wynika, że
1 0 0 1 1 0 1 0 0 0 0 - 1 0 1
będzie podzielne bez reszty przez C(x) a to jest dokładnie co przesyłamy
operacja odejmowania w arytmetyce wielomianów jest logiczną operacją XOR, dlatego w rzeczywistości przesyłamy
1 0 0 1 1 0 1 0 1 0 1
zauważmy, że jest to początkowy komunikat z dołączoną do niego resztą z obliczenia CRC
odbiorca dzieli otrzymany wielomian
P(x) + E(x) przez C(x)

Wszystkie błędy na jednym bicie, kiedy człony xk i x0 mają niezerowe współczynniki.
Wszystkie błędy na dwóch bitach, kiedy C(x) ma czynnik o przynajmniej trzech członach.
Błąd na dowolnej nieparzystej liczbie bitów, kiedy C(x) zawiera czynnik (x+1).
Dowolny błąd "seryjny" (to znaczy sekwencja kolejnych błędnych bitów), którego długość serii jest mniejsza niż k. (Większość błędów o serii dłuższej również może być wykryta).


