Execution Profiler
This chapter covers the following topics:
Introduction
The best way to improve the performance of a program is to change its least-efficient algorithms and data structures, rather than optimize small segments of compiled code. The Execution Profiler identifies which parts of the program are used frequently, helping you pinpoint algorithms that you should modify or rewrite.
Trying to find these bottlenecks without an execution profiler is as difficult as trying to find bugs without a debugger - it can mean having to recode, recompile, and reexecute your program over and over again.
The Profiler can identify things such as:
- where a program spends its time
- how often a source line executes
- how often a routine is called
Profiler components
The Profiler package consists of the Profiler and its accompanying Sampler.
The Sampler takes snapshots of an executing program. It interrupts the program at regular intervals and records which region of the program was being executed at each interrupt.
Since regions that consume large amounts of time have a greater chance of being sampled, the information that the Sampler records provides a statistical measure of how much various regions contribute to execution time. The Sampler saves this information in a sample file.
The Profiler takes the sample file and lets you interactively view the results of the program's execution. Since you can see at a glance how much each region contributes to the execution time, you can quickly pinpoint the instructions that are slowing down the program's performance. With this information, you can go about optimizing your program with minimal recoding.
QNX implementation
Watcom designed the Profiler to operate in several environments, including QNX, DOS, and OS/2. Note that the following features don't apply in a QNX environment:
- overlays
- program marks
- threads
Using the Sampler
The Sampler interrupts a process at regular, timed intervals and samples the segment and instruction pointer of the process on each timer interrupt. It then writes the gathered samples to a file that can later be read and interpreted by the Profiler.
The Sampler samples the process at a rate based on the tick size. To change the sampling rate (you must have superuser privileges to do this), change the tick size with the ticksize utility. A smaller tick size produces a higher sampling rate.
If multiple copies of the Sampler are running, each will record only those samples that apply to the process it's sampling.
Command syntax and examples
sample [options] [command_name [argument...] ]
- -b numbufs
- Use this number of buffers (default is 2). A buffer holds up to 2000 samples.
- -d
- Discard all samples that sample collects while it's writing a buffer.
- -f file
- Save data to this file (default is command_name.smp in the current directory).
- -k
- Keep samples from all processes in the system. By default, sample keeps samples only from the specified process or command.
- -L file
- Use the shared executables specified in this file.
- -l pid
- Use this shared library, where pid is the process ID of the library.
- -p pid
- Sample this process (default is the specified command).
- -q
- Be quiet; don't print information messages.
- -s seconds
- Save this many seconds worth of samples.
- -w
- Wait for all buffers to fill before writing to file.
Examples
Sample process pid 234 until it terminates or Ctrl-C is pressed:
sample -p 234
Run and sample busy until it terminates, Ctrl-C is pressed, or 10 seconds of samples have been gathered:
sample -s 10 busy
Sample process pid 3 until it terminates, Ctrl-C is pressed, or 60 seconds of samples have been gathered; discard samples that occur while writing data to disk:
sample -p 3 -s 60 -d
Using Sampler options
-b numbufs
If sample can save the buffers to a file faster than it fills them with samples, then only two buffers are necessary. But if sample fills them at a rate close to the rate at which it saves them, then you should use -b to increase the number of buffers. This will allow for temporary slowdowns in the data rate to the file without sample loss. Slowdowns may occur if the filesystem is busy with other users or is running across a busy network. Running out of buffers and discarding samples shouldn't affect the reliability of the results.
-d
After sample writes a buffer to a file, it continues by filling the next available buffer, which you might not want to happen. If you're sampling a process that's in the data path to the sample file itself (e.g. Fsys), writing the buffers can modify the execution path of the process as the data flows through it. To avoid this problem, specify -d and sample will discard all samples it collects while it's writing a buffer.
-f file
The sample utility accumulates data in a linked list of memory buffers and writes the buffers to a file as each buffer fills. By default, sample places the file in the current directory with a name formed from the command name appended with .smp. To specify a directory path and filename, use the -f option.
-L file
The -L option lets you sample shared executables. The specified file consists of one or more lines, each one mapping a shared executable to a code segment. (To determine the code segment, execute the command sin memory.)
A line such as:
/bin/Fsys.floppy A5
tells Fsys that when it encounters code segment A5 it should interpret the debug information encoded in the /bin/Fsys.floppy file.
-l pid
The -l option lets you specify a shared library process. This lets sample get debugging information for the routines in that shared library. When you subsequently use the Profiler, you'll see information for those routines.
-p pid
You can sample a process that's already running by using -p, or you can have sample start and monitor a new process by providing a command name. If you specify a running process, you can stop sample either by specifying -s on the command line or by pressing Ctrl-C during sampling.
-s seconds
The -s option lets you collect samples for a specified number of execution seconds. For example, if a process runs only 10% of the time (perhaps it blocks or is preempted by another process), specifying -s 10 should accumulate 10 seconds of samples after about 100 seconds of elapsed time.
-w
By default, sample writes each buffer once it fills. When you specify -w, sample delays writing individual buffers until all are full. It then writes all buffers at once, and continues collecting samples.
Using the Profiler
The Profiler takes the information from the sample file and displays the results in a simple format that lets you quickly identify the regions that contributed most to the execution time. You can then zoom into each of these regions, from the module level down through to the assembly level, to pinpoint which instructions need the most attention.
To access busy regions of a program more quickly, you can hide any region that doesn't contribute significantly to the execution of the program - this is known as cutting. By default, the Profiler hides any regions of code that the Sampler didn't gather data for.
Absolute and relative percentages
When using the Profiler, you normally first look at the percentage figures that show how much each region of code contributed to the execution time. The Profiler displays two types of percentages:
- absolute percentage - the percentage of time a piece of a region contributes to the total execution time of the program.
- relative percentage - the percentage of time a piece of a region contributes to the total execution time of that region.
At the highest level - modules - the region is the entire program, so both percentages indicate each module's contribution to the total execution time. As you zoom into routines and source code, the difference between the two percentages becomes meaningful - a relative percentage then tells you how much a piece of the region contributes to the execution time of that region, not the entire program.
In its main screen, the Profiler displays the percentage for each piece of a region as a number (e.g. 4%); by default, this is an absolute percentage. The Profiler also has a histogram (bar chart) option - by default, this shows relative values so you can see at a glance how various pieces of a region contribute to that region's execution time. You can change either default at any time.
The numeric absolute percentages reflect the true contributions to the total execution time of the program and, as such, are the final arbiters for any decisions you make about optimizing a region of code.
Identifying regions that need attention
Now let's look at how to work with the percentage figures that the Profiler displays. For example, let's say you have a program with three distinct regions and the Profiler tells you that each region's contribution to the execution time is as follows:
| Region | Percentage of execution time |
|---|---|
| 1 | 10% |
| 2 | 70% |
| 3 | 20% |
To improve the performance of a program, you normally first look at those regions that are being used most heavily. Since region 2 contributes most to the execution time (70%), you would first try to optimize that region.
For example, if you were able to double its speed, region 2's contribution to the original execution time might drop from 70% to about 35%. (So if the program originally took 100 seconds to execute, it should now take about 65 seconds.) But if you spent roughly the same amount of work on region 1 to double its speed, you might reduce the original execution time by only 5% instead of 35%.
Apply this strategy to successive levels within a program:
- Identify the modules that contribute most to the execution time.
- Next, within those modules, focus on the routines that contribute the most time.
- Then, within those routines, look at the source lines that contribute the most time.
Starting the Profiler
To invoke the Profiler, enter this command:
wprof [sample_file]
By default, sample files have the same name as your executable, with a .smp suffix. If you don't specify a sample file at the command line, the Profiler will prompt for one.
Once a file is loaded, you'll see a screen similar to the following:
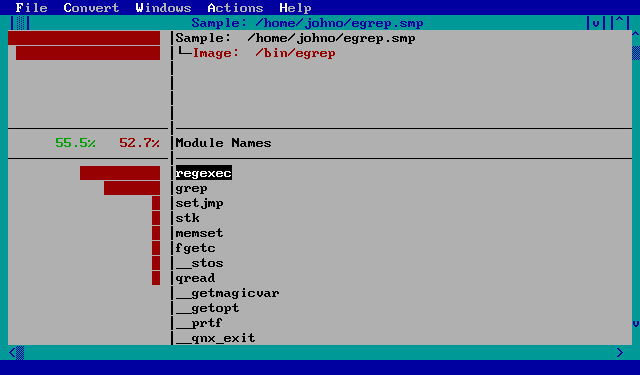
Quitting the Profiler
To exit the Profiler, bring up the File menu and choose Exit (or press Alt-X).
Getting help
The Profiler has an extensive online Help system featuring a table of contents, list of keywords, an index, and a search facility.
To get help, bring up the Help menu (or press Alt-H) and choose Contents (or press Alt-C when the Help menu is displayed).
Menus and keyboard shortcuts
To access each menu (File, Convert, Windows, Actions, Help) as well as the items within each menu, press the Alt key together with the appropriate highlighted letter.
Shortcuts to menus
| To bring up this menu: | Use this keychord: |
|---|---|
| File | Alt-F |
| Convert | Alt-C |
| Windows | Alt-W |
| Actions | Alt-A |
| Help | Alt-H |
From within the File menu...
| To bring up this item: | Use this keychord: |
|---|---|
| Open | Alt-O |
| Close | Alt-C |
| Options | Alt-T |
| System | Alt-Y |
| Exit | Alt-X |
From within the Convert menu...
| To bring up this item: | Use this keychord: |
|---|---|
| Current Module | Alt-M |
| Current Image | Alt-I |
| All Images | Alt-A |